This is the thirteenth part of “An Outsider’s Tour of Reinforcement Learning.” Part 14 is here. Part 12 is here. Part 1 is here.
Can poor models be used in control loops and still achieve near-optimal performance? In recent posts, we’ve seen the answer is certainly “maybe.” Nominal control could learn a poor model of the double-integrator with 10 samples and still achieve high performance. Is this optimal for the LQR problem? Is it really just as simple as fitting parameters and treating your estimates as true?
The answer is not entirely clear. To see why, let’s revisit my very fake datacenter model: a three state system where the state $x$ represents the internal temperature of the racks and the control $u$ provides local cooling of each rack. We modeled this dynamical system with a linear model
\[x_{t+1} = Ax_t + Bu_t+w_t\]Where
\[A = \begin{bmatrix} 1.01 & 0.01 & 0\\ 0.01 & 1.01 & 0.01 \\ 0 & 0.01 & 1.01 \end{bmatrix} \qquad \qquad B = I\]For $Q$ and $R$, I set $Q = I$ and $R= 1000 I$, modeling that the operator wanted to really reduce the electricity bill.
This example seems to pose a problem for nominal control: note that all of the diagonal entries of the true model are greater than $1$. If we drive the system with noise, the states will grow exponentially, and consequently, you’ll get a fire in your data center. So active cooling must certainly be applied. However, a naive least-squares solution might fit one of the diagonal entries to be less than $1$. Then, since we are placing such high cost on the controls, we might not try to cool that mode too much, and this would lead to a catastrophe.
So how can we include the knowledge that our model is just an estimate and not accurate with a small sample count? My group has been considering an approach to this problem called “Coarse-ID Control,” that tries to incorporate such uncertainty.
Coarse-ID Ingredients
The general framework of Coarse-ID Control consists of the following three steps:
- Use supervised learning to learn a coarse model of the dynamical system to be controlled. I’ll refer to the system estimate as the nominal system.
- Using either prior knowledge or statistical tools like the bootstrap, build probabilistic guarantees about the distance between the nominal system and the true, unknown dynamics.
- Solve a robust optimization problem that optimizes control of the nominal system while penalizing signals with respect to the estimated uncertainty, ensuring stable, robust execution.
This approach is an example of Robust Control. In robust control, we try to find a controller that works not only for one model, but all possible models in some set. In this case, as long as the true behavior lies in this set of candidate models, we’ll be guaranteed to find a performant controller. The key here is that we are using machine learning to identify not only the plant to be controlled, but the uncertainty as well.
The coarse-ID procedure is well illustrated through the case study of LQR. First, we can estimate $A$ and $B$ by exciting the system with a little random noise, measuring the outcome, and then solving a least-squares problem. We can then guarantee how accurate these estimates are using some heavy-duty probabilistic analysis. And for those of you out there who smartly don’t trust theory bounds, you can also use a simple bootstrap approach to estimate the uncertainty set. Once we have these two estimates, we can pose a robust variant of the standard LQR optimal control problem that computes a controller that stabilizes all of the models that would be consistent with the data we’ve observed.
Putting all these pieces together, and leveraging some new results in control theory, my students Sarah Dean, Horia Mania, and Stephen Tu, post-doc Nik Matni, and I were able to combine this into the first end-to-end guarantee for LQR. We derived non-asymptotic bounds that guaranteed finite performance on the infinite time horizon, and were able to quantitatively bound the gap between our solution and the best controller you could design if you knew the model exactly.
To be a bit more precise, suppose in that we have a state dimension $d$ and have $p$ control inputs. Our analysis guarantees that after $O(d+p)$ iterations, we can design a controller that will have low cost on the infinite time horizon. That is, we can guarantee that we stabilize the system (we won’t cause fires) after seeing only a finite amount of data.
Proof is in the pudding
Let’s return to the data center problem to see how this does on real data and not just in theory. To solve the robust LQR problem, we end up solving a small semidefinite programming problem as described in our paper. Though I know that most people are scared to run SDPs, for the size of the problems we consider, these are solved on my laptop in well under a second.
In the plots below we compare nominal control to two versions of the robust LQR problem. The blue line denotes performance when we tell the robust optimization solver what the actual distance is from the nominal model to the true model. The green curve depicts what happens when we estimate this difference between the models using a bootstrap simulation. Note that the green curve is worse, but not that much worse:
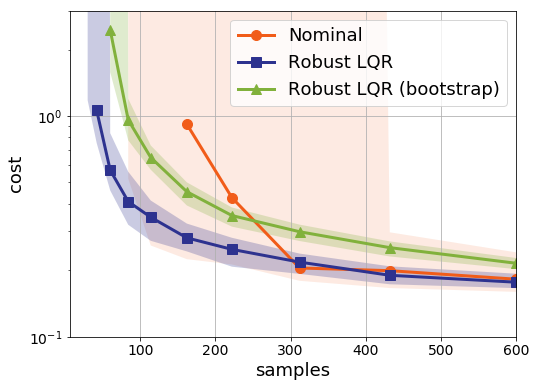
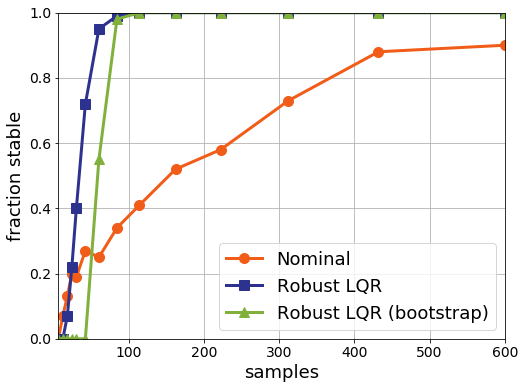
Note also that the nominal controller does tend to frequently find controllers that fail to stabilize the true system. The robust optimization really helps here to provide controllers that are guaranteed to find a stabilizing solution. On the other hand, in industrial practice nominal control does seem to work quite well. I think a great open problem is to find reasonable assumptions under which the nominal controller is stabilizing. This will involve some hairy analysis of perturbation of Ricatti equations, but it would really help to fill out the picture of when such methods are safely applicable.
And of course, let’s not leave out model-free RL approaches:
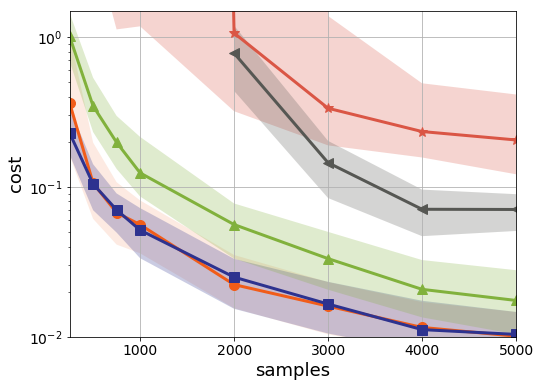
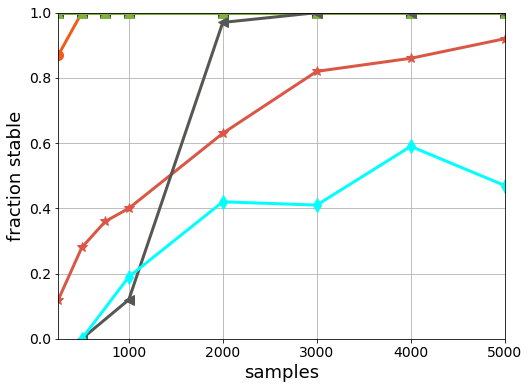

Here we again see they are indeed far off their model-based counterparts. The x-axis has increased by a factor of 10, and yet even the approximate dynamic approach LSPI is not finding decent solutions. It’s worth remembering that not only are model-free methods sample hungry, but they fail to be safe. And safety is much more critical than sample complexity.
Pushing against the boundaries
Since Coarse-ID Control works so well on LQR, I think it’s going to be very interesting to try to push its limits. I’d like to understand how this works on nonlinear problems. Can we propagate parametric uncertainties into control guarantees? Can we model nonlinear problems with linear models and estimate the nonlinear uncertainties? There are a lot of great open problems following up this initial work, and I want to expand on the big set of unsolved problems in the next post.